In the past, I've applied AI tools for coding in HTML/CSS/JS, Python, and R. While the results are far from perfect, they tend to work relatively well after some minor adjustments. However, Julia is a less popular language, and hence there's a limited amount of information to train AI models. Despite this limitation, can we expect AI tools to perform decently well when applied to Julia?
The post explores this question by focusing on free AI tools. The conclusion is that these tools applied to Julia tend to perform quite poorly. My claim is supported by two reasons.
First, the suggested Julia code often requires more than simple adjustments—it's not uncommon for the code to need a complete rewrite, unlike what occurs with more popular languages.
Second, AI chatbots perform particularly poorly at explaining how the Julia language works. This is a more severe issue than the first one, as it affects new learners disproportionately and incorrect explanations aren't as easy to spot as invalid code. In fact, it's quite common obtaining answers based on other languages. This is likely arising because of the limited Julia data, combined with ample information for other languages. As an example, all the AI chatbots consistently claim that vectorized code is faster than for-loops in Julia, and even discourage the use of functions. Similarly, the AIs state that Julia creates views of slices by default, rather than copies. [note] ChatGPT-4 was providing different answers, depending on the question asked.
On a more positive note, AI tools seem pretty efficient at constructing regular expressions in Julia. This is remarkable, as writing regular expressions isn't particularly hard, but can quickly become tedious. [note] To avoid a lengthy post, examples with regular expressions aren't included. I'll probably write a separate post about it.
Overall, the main message is that you should be cautious when using AI tools for coding, but even more so when applying them to Julia. This becomes particularly relevant if you rely on AI tools to learn the language itself.
I present the outputs from several sample prompts to illustrate my impressions of AI tools for Julia coding.
I only consider free options, which include ChatGPT-3.5, ChatGPT-4, Bard, Claude-2, and LLaMA2-70b. You can freely access each as follows.
ChatGPT-3.5, Claude-2, and LLaMA2-70b: accessed through poe.com. The first two models can also be accessed directly through their websites. The less performant version Claude-1 yields similar results to Claude-2 for Julia.
ChatGPT-4: accessed through www.phind.com. A couple of free messages per day are also available through poe.com.
Bard: accessed directly through bard.google.com. For countries where Bard is not available (e.g., Canada), it can still be freely accessed. This requires installing Opera browser, which has a basic built-in VPN. The same method can be applied to access Claude-2 through its official website (only available in the USA and UK without a VPN), rather than through Poe.
There are two key points you can appreciate from the results.
ChatGPT-4 seems to be the top option at the moment, although its performance when applied to Julia is not breathtaking. Yet, it signals the possibility of better free alternatives arriving quite soon. Indeed, given the quick advances in the field, it's highly likely that this post will become obsolete within just a few months!
LLaMA2-70b and Bard are the worst alternatives. Furthermore, I was expecting a better performance from Claude-2—I had previously used it for various tasks, and their results were outperforming ChatGPT-3.5 in several domains.
All code has been checked under Julia 1.9.2.
I consider two examples. The first one describes the task concisely, without any explanation. This helps us identify whether any problems stem from the user's formulation or the AI's ability to code in Julia. The second example considers a more specific task, for which I provide clarifications. Overall, the solutions suggested by the AI accomplish their purpose, but tend to be more complex than necessary.
I deliberately provided a short vague prompt, by not defining the concepts of "normalize" and "share".
PROMPT: Provide some code in Julia that normalizes a vector, expressing each entry as a share.
I now consider a more specific task and provide some hints to guide the AI. The objective is to identify whether the AI can provide a brief efficient solution when it has a clear understanding of the user's needs.
PROMPT: Provide some code in Julia that, given a vector x, provides a vector y with the ranking position of x. The index 1 of y has to represent the highest value of x. For instance, given x=[2,10,1,0], we should obtain y=[2,1,3,4].
For this test, I also consider two examples. The first one asks the AIs to enhance some existing code, whereas the second one asks the AIs to rank three code snippets by performance.
The example considers a code snippet that is clearly inefficient due to the use of global variables. The goal was to identify whether the AIs would suggest wrapping the code in a function. None of them did it.
# The following code is written in Julia to compute 'y'.
# Rewrite it to speed up its computations.
x = rand(1000)
y = zeros(length(x))
for i in eachindex(x)
y[i] = sum(x[i:end]) / i
endAll the models provide similar answers if you clear the chat and re-execute the prompt, so this feature is not determining the results. The only exception is Bard, which provides different answers. It occasionally suggested performant code, but due to incorrect reasons. [note] For instance, several times it wrapped the code in a function, without any reference to why it was doing it. Quite likely, the use of functions was actually responding to a "hallucination", where it provided computation times by executing @btime.
For ChatGPT-4, I additionally tested other prompts. The aim was to ensure that the model wasn't assuming I'd eventually wrap the code in a function. The results were identical. Furthermore, I asked whether the code suggested was "a more" efficient or "the most" efficient solution, for which it indicated that "the provided solution is the most efficient for this specific problem."
It's also interesting that Phind has the capability of accessing the internet. This makes the incorrect answer more surprising, as it reports "Performance Tips" as one of its sources. This webpage is part of the official documentation, and its first recommendation is to wrap code in functions to avoid the use of global variables.
The example provides three code snippets to the AIs, all of which return the same output. Then, the task of the AI is to rank each code by performance. This makes it possible to identify whether the AIs provide a correct answer, but also assess the explanations outlined. Only ChatGPT-4 was able to do it.
# I'm using Julia and have codes named 'code 1', 'code 2', and 'code3'.
# If I execute each as they're written, which code should be faster?
# Rank them by speed.
##### CODE 1 ######
x = rand(100_000)
y = similar(x)
function example1(x,y)
for i in eachindex(x)
y[i] = log(x[i] + 1) ^ x[i]
end
return y
end
example1(x,y)
##### CODE 2 ######
x = rand(100_000)
y = similar(x)
function example2(y)
for i in eachindex(x)
y[i] = log(x[i] + 1) ^ x[i]
end
return y
end
example2(y)
##### CODE 3 ######
x = rand(100_000)
y = similar(x)
for i in eachindex(x)
y[i] = log(x[i] + 1) ^ x[i]
endThe results are as follows.
| ChatGPT-3.5 | ChatGPT-4 | Claude-2 | Bard | LLaMA2-70b |
|---|---|---|---|---|
| Code 3 > Code 1 > Code 2 | Code 1 > Code 2 > Code 3 | Code 3 > Code 2 > Code 1 | ||
ChatGPT-3.5 indicates that Code 3 is the fastest because "it preallocates the memory for `y` before the loop, which can be more efficient than allocating it within the loop ". Conversely, Claude-2, Bard, and LLaMA2-70b reach the same conclusion, but because "Code 3 avoids the function overhead of Code 1 and Code 2".
ChatGPT-4 is the only model that provides the correct answer. Furthermore, it offers an appropriate analysis of each option.
Code 1 is "good practice as the function is self-contained and does not depend on any global variable."
Code 2 "directly uses the global variable x. This can slow down the execution as global variables in Julia are not as efficient as local variables."
Code 3 "is the least efficient among the three codes due to the heavy use of global variables."
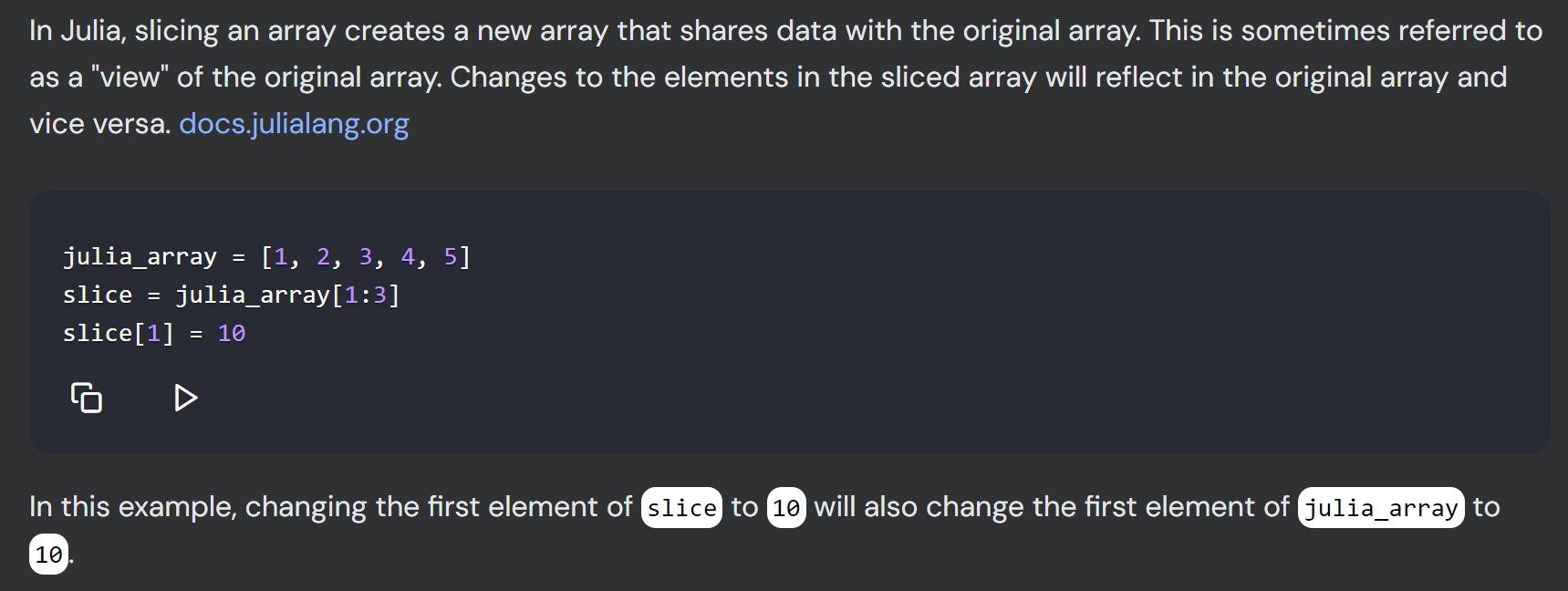
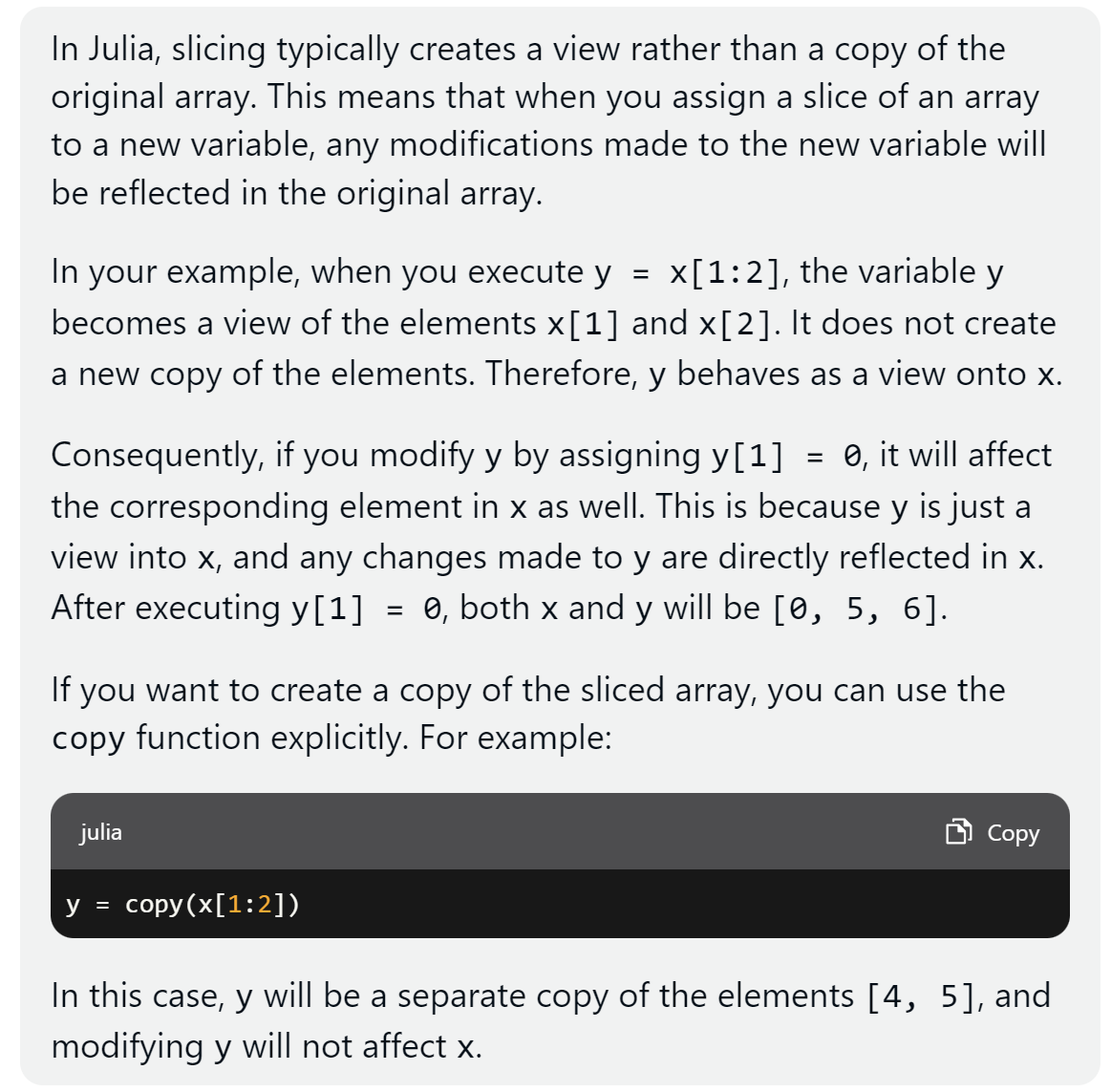
Finally, I tested whether the AI tools could be helpful to learn the Julia language. This was done by asking about the slicing behavior in Julia.
The prompt was as follows.
# What's the behavior of slicing in Julia? Does it create a copy or a view?
# For instance, given
x = [4,5,6]
y = x[1:2]
# does y behave as a copy or a view? what are the consequences on `x` of executing `y[1] = 0`?And the results are the following.
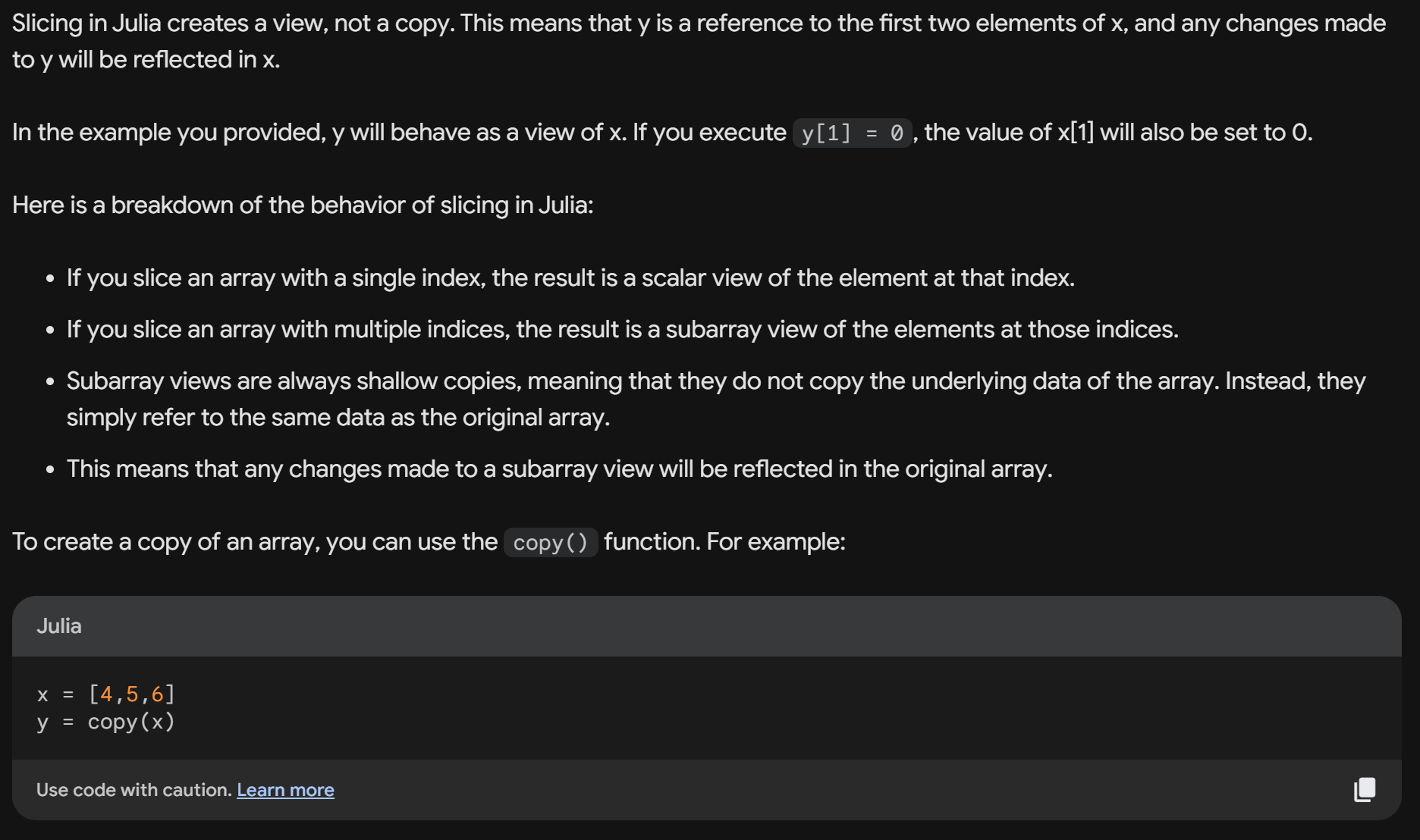
While ChatGPT-4 provided the right answer above, this wasn't always the case. For instance, this is what occurs when I made the AI compare the slicing behavior in Julia and NumPy (the figure is restricted to the answer for Julia).